国総研レポート2020(研究期間 : 令和元年度)
国土技術政策総合研究所 社会資本マネジメント研究センター 社会資本情報基盤研究室
主任研究官 大手 方如
情報研究官 菅原 謙二
室長(博士(工学)) 池田 裕二
交流研究員 細川 武彦
(キーワード) AI,CCTVカメラ,被害把握,画像処理
1.はじめに
国土交通省は道路や河川を管理する目的で、全国に2万台以上のCCTV(Closed Circuit Television)カメラを設置していて、地震発生後の被害状況の情報収集にも活用している。活用にあたり、特に大規模震災時において、広い範囲にある多数のCCTVカメラ映像を目視し、被害状況が映っているかを迅速に確認することは災害対応を行う職員にとって負担が大きいという課題がある。
この課題を解決するために、国総研は平成26年度から平成30年度にかけて震災発生前後の画像から被害の可能性がある「変化」を差分として検出する技術(以下、差分検出という。)を開発した。
一方、これまでの研究により、差分検出には、季節や天候によって、映り込んでいる雨・雪等を被害の可能性がある「変化」と誤検出してしまう課題があることが分かっている(図-1)。そこで、今年度はAI(Artificial Intelligence)を用いて差分検出の誤検出を減少させる技術の研究を行った。
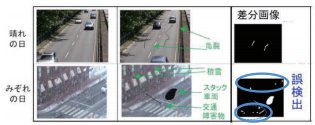
図-1 悪天候時による誤検出の例
2.AIのアルゴリズムの選定について
差分検出を行う前段階でAIによる画像処理を行い、後段の差分検出での誤検出を減少させる手法につい
検討を行った。教師データとして多くの被害画像を準備することが困難であることから、本研究ではAIのアルゴリズムとして、教師データに被災状況の画像を必要としない「セマンティック・セグメンテーション」と「GAN:敵対的生成ネットワーク(Generative Adversarial Networks)」という2つのアルゴリズムを比較検討した。
「セマンティック・セグメンテーション」とは、平常時の画像に「道路」「川」といった領域の情報(以後、アノテーションという。)を付加したデータを教師データとして機械学習させたモデルを用いて、入力した画像がどの領域を映しているかを検出するためのアノテーション画像を生成するものである。図-2に平常時の画像と教師データに用いるアノテーション画像の例を示す。

図-2 平常時のCCTVカメラ画像(左)とアノテーション画像(右)
「GAN」とは、たとえば馬の画像のみを学習させたモデルにシマウマの画像を入力すると、馬に似た部分の画像を馬の特徴をとらえた画像へ変換するというアルゴリズムである(図-3)1)。これを応用して、様々な季節や天候における平常時の画像を学習させたモデルに被害画像を入力すると、季節や天候の状況はそのままで被害状況のみが消えたあたかも被災前の画像が生成できる可能性がある。この生成された画像と入力画像との差分検出を行うことにより被害状況のみを検出することを試みた。

図-3 GANによる画像生成の例。入力画像(左)、出力画像(右)
セマンティック・セグメンテーションとGANについて、少ない教師データ数(セマンティック・セグメンテーションは110枚、GANは790枚)で試行した。
セマンティック・セグメンテーションでは安定したアノテーション画像が得られる傾向があったのに対して、GANはCCTVカメラごとにモデルを作成しないと生成される画像が安定しなかった。よって、本研究においてはセマンティック・セグメンテーションを選定し、モデル構築及び精度評価を行った。
3.セマンティック・セグメンテーションのモデル構築及び精度評価結果について
道路・河川・広域監視用CCTV画像の静止画から教師データとするアノテーション画像を500枚作成した。500枚のうち学習用に350枚、学習状況の検証用に75枚、試験用に75枚を用いた。既存のデータセット2)で学習済みのモデル3)に対し、学習用350枚のアノテーション画像を用いて強化学習を行ったモデル(以下、本モデルという。)を構築し、本モデルについて精度評価を行った。本モデルによって生成されたアノテーション画像の例を図-4に、精度評価結果を図-5に示す。なお、精度評価にはIoUという画像認識における物体検出の評価指標を用いた。IoUは(1)で表される。
![]()
Intersection:正解画像と生成画像の同じエリアが重なっている領域
Union:正解画像と生成画像のどちらかのエリアが占めている領域

図-4 平常時のCCTVカメラ画像(左)、正解アノテー
ション画像(中)、生成されたアノテーション画像(右)
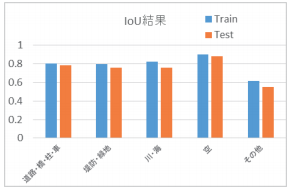
図-5 構築したモデルのIoUによる評価結果
Train:モデル構築用のデータの評価結果
Test:試験用のデータの評価結果
公開されている様々なセマンティック・セグメンテーションのIoUは最大で0.8~0.9の間である4)。よって、学習用データが350枚と限られた状況においては、本モデルの精度検証結果は概ね妥当であると考えられる。
4.本モデルを用いた誤検出を減少させる技術について
本モデルを用いた誤検出を減少させる技術は、差分検出の前処理として画像の領域を認識するアノテーション画像を自動生成することで、検出された被害候補箇所がどの領域にあるかわかるため、その領域における被害画像の特徴を考慮することで、より誤検出の少ない被害箇所の検出の実現が期待される。
5.おわりに
今後、誤検出低減技術について、降雪や降雨時の画像を用いて効果を検証し、改良を進めるとともに、災害対応支援のための取り組みを行っていく予定である。
☞詳細情報はこちら
1)https://arxiv.org/pdf/1703.10593.pdf
2)http://host.robots.ox.ac.uk/pascal/VOC/
3)https://towardsdatascience.com/deeplabv3-c5c749322ffa
4)https://paperswithcode.com/sota/semantic-segmentationon-pascal-voc-2012

